大模型专栏第十五期|多模态大模型的安全挑战:LVLM攻击技术综述与未来展望
大模型专栏第十五期
近年来,人工智能大模型发展迅猛,已成为推动技术演进与产业变革的核心动力。与聚焦文本处理的大规模语言模型相比,大规模视觉-语言模型(Large Vision-Language Model, LVLM)更贴近现实应用场景,在多模态理解和推理任务中表现卓越。
得益于数据量、模型规模、计算资源的持续增长,LVLM在文本生成图像、视觉问答、图像描述生成、图文检索等领域成绩斐然,却也存在多种安全威胁和漏洞风险。因此,多模态大模型攻击引起了研究者的广泛关注。
本期大模型进展专栏“顶会顶刊分享栏目”,我们特邀近地面探测全国重点实验室陈玄真老师,为大家解读2025年LVLM攻击领域的最新综述成果——发表于IEEE TNNLS的综述,介绍LVLM攻击的背景知识、发展历程和潜在方向。
论文信息
Title: A Survey of Attacks on Large Vision-Language Models: Resources, Advances, and Future Trends
Author: Dai-zong Liu, Ming-yu Yang, Xiao-ye Qu, Pan Zhou, Yu Cheng, Wei Hu.
Affiliation: Wangxuan Institute of Computer Technology, Peking University
Journal: IEEE Transactions on Neural Networks and Learning Systems
一、LVLM攻击的研究背景
LVLM攻击定义
对两个输入模态(图像、文本)施加攻击操作,从而使LVLM模型产生错误输出、越狱输出或攻击者选定输出。
LVLM攻击的挑战
LVLM攻击面临的挑战源于复杂架构、输入多模态特性、安全措施演变等方面。深入理解这些挑战,对于制定有效攻击策略或提升模型鲁棒性至关重要。
1、多模态复杂性:有效攻击必须开发出能同时欺骗视觉组件和文本组件的对抗样本,难度远超单模态攻击情况。
2、模型可扩展性:LVLM规模庞大、结构复杂,参数量高达数百万。向LVLM实施传统对抗性攻击需要强大的算力支持。
3、攻击实际情况:现有LVLM攻击依赖模型先验知识,或借助替代模型。然而,实际应用中,用户无法获悉模型细节,只能通过查询来实施攻击。
4、攻击的不可察觉性与迁移性:想要不知不觉地完成高质量攻击,应该保持良性样本的语义特征,有效欺骗人类或机器人的视觉系统;这就需要严格限制扰动类型和扰动幅度。此外,现有攻击通常针对特定模型设计,攻击效果很难在相似架构模型之间泛化。
5、可解释性与可理解性攻击:想要实施真正有效的攻击,攻击者需要深入理解LVLM的工作和决策流程。然而,LVLM的黑盒本质与高复杂度耦合,难以对攻击成败作出解释。
6、鲁棒性防御:许多LVLM内置了动态防御机制,能够根据检测到的对抗性攻击活动灵活调整。防御措施包括实施监控、异常检测、自适应重训练等。因此,攻击策略必须不断演进,持续领先于自适应防御手段,这需要大量计算资源和复杂精妙的算法。
LVLM攻击的当前资源
1、白盒攻击工具
白盒攻击能充分利用模型的架构、参数、梯度等信息。攻击者获取了全访问的访问权限,能够精心设计对抗性样本,从而有效利用模型中的特定漏洞。
快速梯度符号法(Fast Gradient Sign Method, FGSM):最早且最广为人知的白盒攻击方法;对输入数据沿损失函数梯度方向微调,生成对抗样本。
投影梯度下降法(Projected Gradient Descent, PGD):FGSM的迭代优化版本。
C&W攻击方法:采用复杂目标函数优化扰动,能够灵活、高效地生成最小扰动对抗样本。
2、灰盒攻击工具
灰盒攻击仅掌握部分模型信息,如:架构或某些内部参数,而无法完全访问模型权重或完整训练数据。
3、黑盒攻击工具
黑盒攻击者通常无法获取模型的架构或参数,只能通过查询模型并观察其输出来实施攻击。
简单黑盒攻击(Simple Black-box Attack, SimBA):利用随机搜索添加扰动,通过评估扰动对损失的影响决定是否接受。
随机无梯度法(Random Gradient-free, RGF):在输入空间随机采样,根据模型输出差异估算梯度,进而执行对抗攻击。
查询受限黑盒攻击:尽量减少对目标模型查询次数。
4、数据集
(1)通用视觉任务数据集:与目标检测、视觉问答等标准视觉任务相关。攻击场景中,这些数据集作为生成对抗样本的原始数据。
(2)安全相关数据集:聚焦大模型的安全性问题。
(3)采用生成式大模型构建专属数据集。
5、LVLM模型
LVLM攻击对象通常是代表性LVLM,如:Flamingo、MiniGPT-v2、LLaVA;除开源的多模态大模型外,攻击者也在黑盒测试中评估一些专有多模态大模型,如:GPT-4V。
6、评估指标
大多数攻击采用攻击成功率(Attack Success Rate, ASR)=成功攻击次数/总攻击次数作为衡量攻击有效性指标。对于不同下游任务或攻击目标,ASR具体含义和计算方式也存在差异。从语义角度评价攻击效果时,可将常见方法分为三类:
(1)人工评价:通过人类判断,来衡量内容的语义相似性或毒性,能更真实、更准确地反映模型输出是否符合攻击者预期。该方法需要大量人力投入,不适合大规模数据集评估。
(2)基于规则的评估
可明确定义为分类任务的安全场景:F1分数、准确度。
精细语义判断场景:BLEU-4、METEOR、CIDEr、SPICE、SSIM。
(3)基于模型的评估
利用辅助语言模型衡量语义相似性或毒性。该方法通常分析高层次语义相似性,能更细致地评估内容一致性,但对计算资源有较高要求,且缺乏可解释性。
7、防御策略
(1)推理阶段防御
提示词工程:通过设计和优化提示词来增强模型防御机制。
匿名检测:检测多模态越狱攻击。
(2)训练阶段防御
鲁棒文本反馈/提示词:构建鲁棒自然语言反馈或鲁棒文本提示,来抵御潜在攻击。
微调/对比学习:通过进一步微调或对比学习,以训练鲁棒LVLM。
二、LVLM攻击的方法论
LVLM攻击分类
对抗攻击:利用模型鲁棒性方面漏洞;
越狱攻击:突破安全限制;
提示词注入攻击:通过调整提示结构来操控模型对输入的解读方式。
数据污染/后门攻击:在训练数据中恶意植入恶意信息以破坏模型性能。
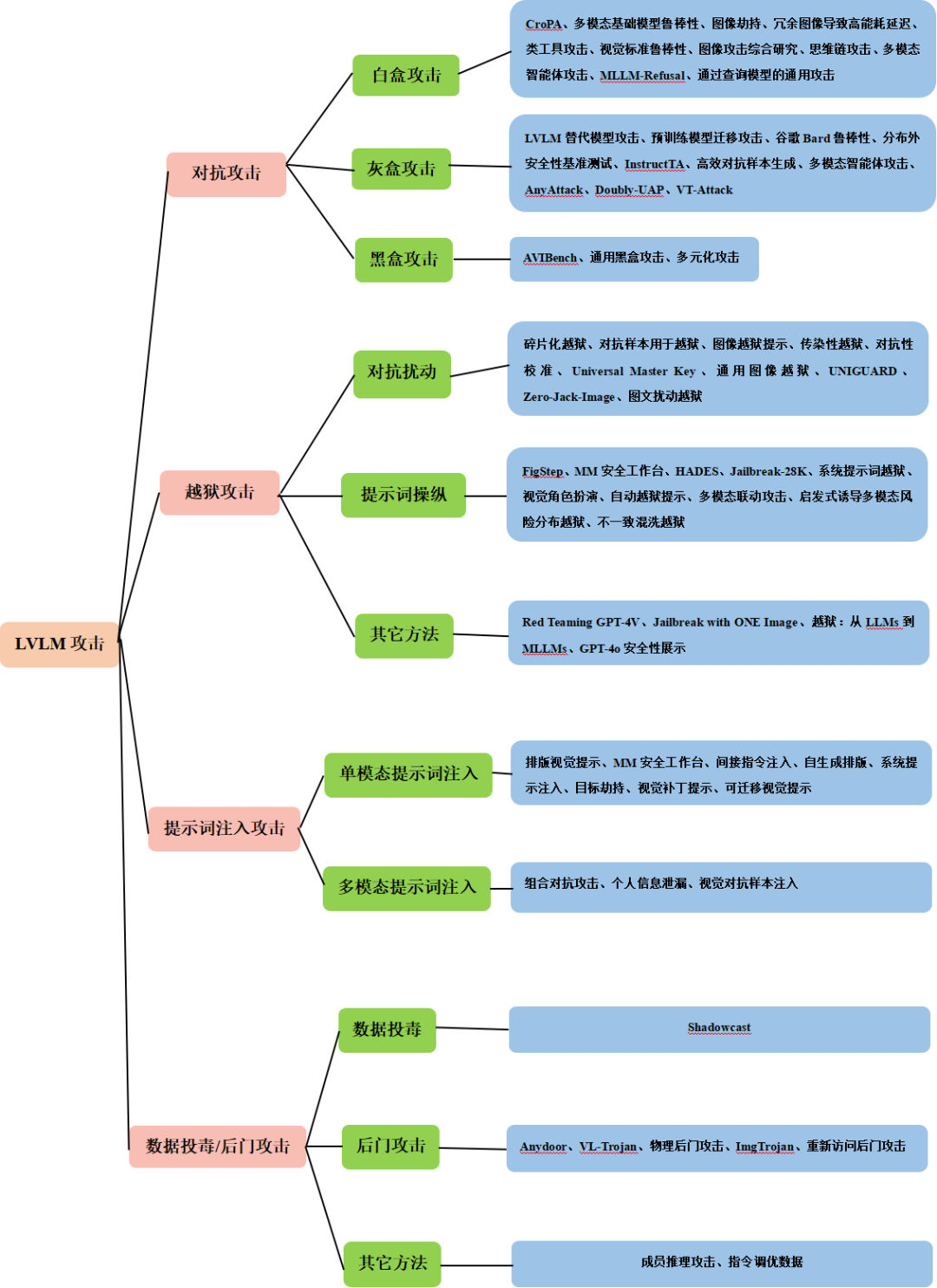
对抗性攻击
以人类难以察觉的方式,对输入数据进行微小扰动,却能导致模型产生错误的或不希望的输出。根据攻击者对目标模型的访问权限不同,可分为:
1、白盒攻击
利用对模型架构、参数及梯度的完全访问权限。
2、灰盒攻击
攻击者仅掌握部分模型信息(架构或部分内部参数),但无法完全访问模型权重或完整训练数据。
3、黑盒攻击
黑盒攻击者通常无法访问模型的架构或参数。
4、总结与分析:现有的大语言视觉模型(LVLM)对抗攻击大致可分为白盒、灰盒和黑盒三种场景。早期的大多数研究主要集中在简单白盒环境下的对抗扰动设计上。尽管这些方法能够实现显著的攻击效果,但它们严重依赖于对LVLM细节的先验知识——而在实际应用中,获取这些信息往往成本高昂或根本无法获得。因此,近年来的研究更多地关注资源受限的灰盒和黑盒场景。不过,灰盒攻击仍需借助大型视觉编码器或其他生成模型等替代模型的知识。尽管如此,这类方法为迁移攻击的设计提供了颇具前景的方向:它们通过抽象视觉编码器的视觉理解能力,巧妙地添加扰动,从而生成与视觉内容无关的特征。此外,目前针对黑盒攻击的解决方案仍寥寥无几。如何深入探究并模仿LVLM的推理能力,以设计出更具针对性的LVLM感知型攻击,同时有效缩短耗时的查询过程,仍是当前黑盒场景下亟待解决的关键问题。
越狱攻击
通过操纵输入来破坏模型训练的知识对齐,导致模型输出有害内容或未授权内容。根据具体实施技术,将越狱攻击分为:
1、基于对抗扰动的攻击
通过设计对抗性图像或文本,以绕过模型内部的对齐机制。
2、基于提示操纵的攻击
通过篡改视觉或文本提示中的内容,降低模型对有害输入的敏感度,或将有毒查询伪装成无害输入,从而绕过模型的安全对齐机制。
3、其它方法
从全新视角提出LVLM越狱攻击方案。
4、总结与分析:与对抗性攻击相比,越狱攻击的潜在威胁大、适用范围广。因此,许多基准测试工作提出用ASR和保留分数等不同角度评估越狱性能。然而,由于LVLM的越狱输出形式多样,当前迫切需要一种全面的越狱测评工具。基于对抗性扰动的越狱攻击通常利用单模态或跨模态的对抗性模式,欺骗跨模态对齐模块,从而导致错误推理过程。不过,这些研究大多依赖白盒环境,在实际应用中难以部署。未来,此类攻击研究应更注重降低资源成本和知识依赖性。尽管基于提示操纵的越狱攻击对额外知识依赖较少,实用性更好,但其隐蔽性和效率仍有待提升。
提示注入攻击
将有害指令注入视觉或文本提示中,以操纵模型输出或诱导其“越狱”,从而引发有害行为。根据使用模态不同,可分为:
1、单模态提示注入攻击
仅将恶意指令注入到单一模态的输入中,即视觉或文本输入。
2、多模态提示注入攻击
同时影响文本和视觉两种模态,通过向多种模态中注入恶意语义,提升绕过对齐屏障的可能性。
3、总结与分析:通过注入易受攻击的视觉或文本提示,误导LVLM推理过程,导致目标性或非目标性的输出,甚至引发“越狱”行为。多数已有的提示注入攻击集中于单模态提示注入,并已取得显著效果。然而,这类攻击中的视觉提示通常较为明显。鲜有研究探讨多模态提示注入问题,因此仍有大量改进空间,如:设计多重密钥激活机制以增强隐蔽性,以及引入跨语义一致性学习方法来提升攻击的有效性。
数据投毒/后门攻击
在微调阶段或人类反馈强化学习(RLHF)过程中,利用恶意数据污染模型导致模型学习到有害模式,或植入触发机制,从而引发恶意行为。
1、数据投毒
将恶意数据引入微调或RLHF数据集中,导致多模态大模型学习到错误的模式,进而可能在后续推理中引发错误。
2、后门攻击
在训练数据中秘密嵌入一个触发模式,使得模型对干净输入表现正常,但在检测到特定触发条件时,却会生成攻击者期望的输出。
3、其它方法:成员推理攻击
4、总结与分析:考虑到资源限制,多数研究集中于后门攻击和其它方法;数据投毒需要对整个训练数据进行复杂控制,引起关注较少。值得注意,后门攻击为LVLM在下游应用的对抗性研究提供了方向,如:自动驾驶、具身智能、机器人学等。一旦这些应用部署了基于恶意数据集训练的模型,攻击者便能轻易误导LVLM推理过程,导致有害输出。后门攻击在LVLM应用落地的探索仍不充分,亟需进一步研究。
三、LVLM攻击未来发展方向
提供攻击实用性
亟需设计一种适用于所有任务样本的通用扰动,并仅通过查询LVLM模型即可实现梯度估计。
自适应与可迁移攻击
深入理解不同模型和任务之间对抗样本的迁移性,开发更具通用性的攻击方法。
跨模态对抗样本
未来研究应致力于探索全新方法,以同时对视觉和文本输入施加具有强关联性的对抗性扰动;深入分析各模态间的相互作用与依赖关系,构建能有效规避现有防御机制的跨模态攻击。
基于数据偏见的攻击
LVLM对数据需求量大,需要大量经过全面标注的数据进行训练。因此,这些模型很容易继承甚至放大其训练数据中存在的偏见。未来研究可聚焦于深入理解、识别并缓解这些偏见,以确保模型产生公平且公正的输出。
人类与AI联合攻击
将人类智慧与人工智能能力相结合,提供了一种强有力的攻击实施方法,如:人机协作攻击、社交工程与操纵。
综合基准测试与评估
为确保LVLM对多种攻击方法的鲁棒且安全,全面的基准测试与评估框架至关重要。这不仅有助于评估当前 LVLM 抵御攻击的能力,还能为开发更强大的模型提供指导,如:标准化LVLM攻击基准测试、持续评估框架、鲁棒性指标与评估标准。
四、指控应用案例
LVLM攻击在指挥控制领域的潜在应用:
(1)多模态信息融合
通过对抗攻击,可以对图像、文本等输入施加扰动,使得LVLM在执行目标识别、态势判断和威胁辨识时产生错误输出,导致指挥员对战场形势作出错误判断。
(2)决策生成
利用大模型的推理能力,特别是思维链构造能力,根据目前的输入态势和预先设定的规则、条令库,为智能体生成任务规划等决策过程。
五、其它参考文献
赵亮,鞠鸿彬,张鹏翼,等. 大模型的能力边界与指挥控制应用 [J]. 指挥与控制学报,2024,10(6):653-660
大模型进展专栏由中国指挥与控制学会主办,大模型与决策智能专委会承办。大模型进展专栏联系方式:lmdi123@163.com 欢迎投稿
文字:陈玄真
编辑:张钊,梁星星,邢天,闫云龙,江禄民
审核:张国华